Vendure Tooling: Overview of a Modern Developer Toolchain

This includes things like:
fixing formatting and code style issues
managing releases and changelogs
creating and updating documentation
verifying that it all works
Whenever these tasks are done manually you will almost certainly:
Forget to do something you should have done
Do something wrong
Spend an inordinate amount of time either trying to avoid, or dealing with the consequences of, 1 and 2.
Therefore it behooves the developer to be able to automate as much of this non-creative work as possible, both to save time better used for thinking and writing code, and to reduce errors and oversights in established processes.
In this blog post I will cover how the Vendure project makes use of a number of tools to do just that. While Vendure is a full-stack Node.js / TypeScript project, several of the tools - and all of the underlying principles - are applicable to other tech stacks. I'll start with the easier-to-implement, "low-hanging fruit" tools and progress into some more sophisticated tools and workflows.

Linting & Formatting
One of the simplest measures to improve the consistency of your code base is to implement automated linting and formatting. Vendure is written in TypeScript and uses tslint as a linter and Prettier as a formatter. Prettier is also run on the HTML templates of our web client (which is an Angular application).
To make the linting fully automated, we use husky and lint-staged so that tslint and Prettier get run before each commit, only on those files which have changed. Linting & formatting the entire repo (~6,000 .ts files) can take a while, whereas the typical commit requires only a handful of files be processed. This ensures no badly-formatted code ever makes it into the repo, while keeping the development workflow fast.
Commit Messages & Changelogs
Maintaining an accurate changelog for each release is crucial for the users of your project, yet it can be very time-consuming and error-prone to try to do manually.
Vendure uses the Conventional Commits style, which provides a standard format for all commit messages. The standard dictates commit messages like this:
fix(core): Correctly prefix asset urls for resolved properties
Closes #146This format is enforced by commitlint which will check the message of each commit, and reject those that do not conform to the standard.
Once we have all our commits in this format, we can then automate the creation of changelogs with Conventional Changelog. This package allows us to look up all the commits since the last tagged release, and extract those commit messages relevant to the changelog (in our case, commits marked "fix", "feat" or "perf"). We then use these messages to update the changelog, including links to each commit and any referenced GitHub issues. Take a look at the Vendure changelog for an example of the output.
Documentation
Documentation is a key ingredient of a healthy project. Projects with little or no documentation will put off most developers and frustrate the remainder, while outdated or inaccurate docs are perhaps even worse.
Keeping documentation accurate and up-to-date involves a significant amount of diligence and time. On a large project, a manual approach almost inevitably results in outdated documentation fragments left dotted around.
Vendure attempts to mitigate this problem by generating the bulk of the documentation of its TypeScript and GraphQL APIs directly from the source code. Both TypeScript and GraphQL have the advantage of being statically-typed languages. Furthermore, both the typescript and graphql npm packages come with code-parsing functions which allow you to turn your source files into abstract syntax trees (ASTs) (if you are not familiar with the idea of ASTs, check out these interactive examples of the GraphQL AST and TypeScript AST). Once parsed into an AST, the rich type information as well as JSDoc-style comments can be used to generate the documentation.
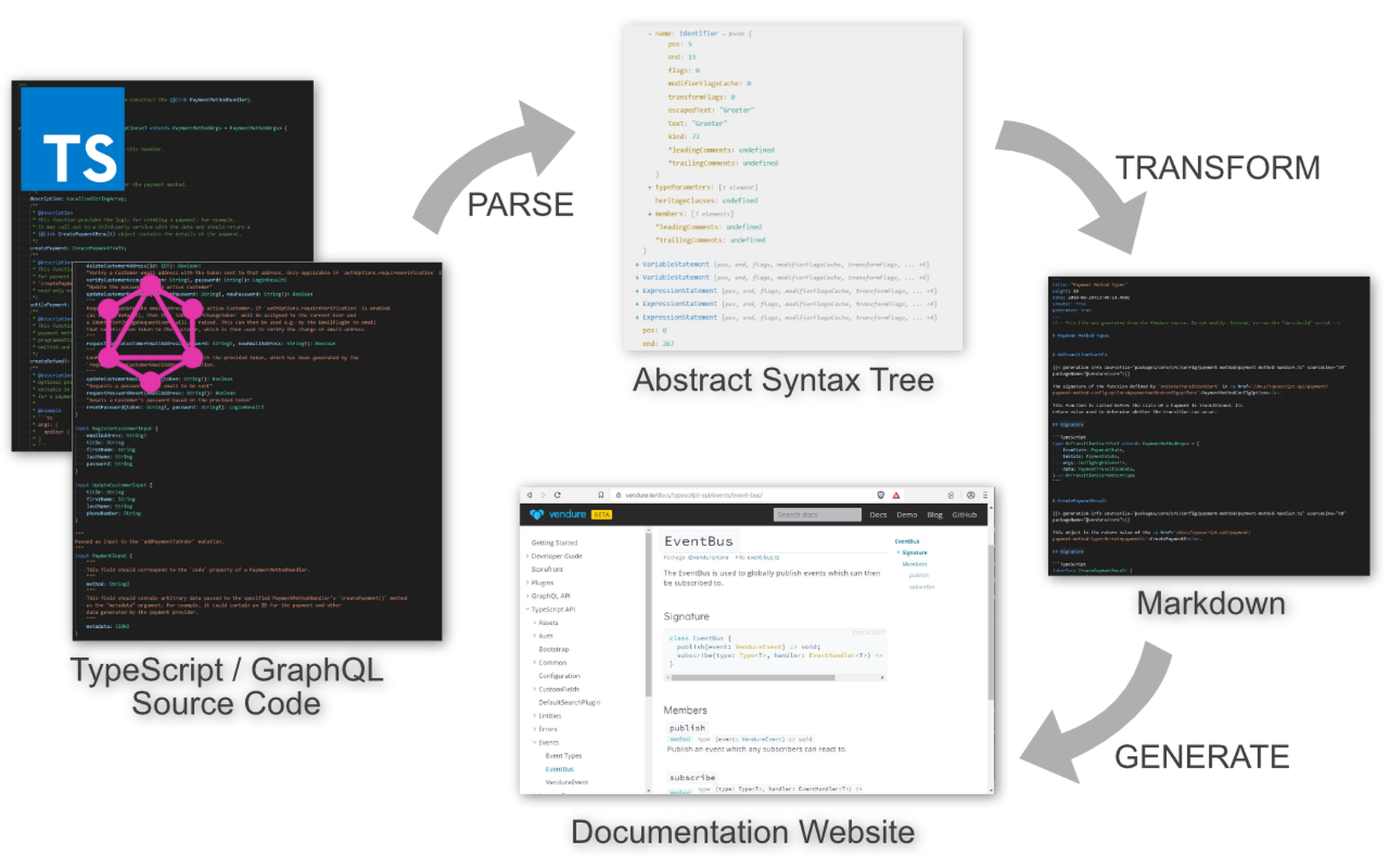
In Vendure we use a few custom scripts to parse the source code and render the resulting AST into markdown files. These markdown files are then used to generate our documentation pages with Hugo (a static site generator which is also used to generate this blog post!). Where more context and explanation is needed than the raw source code can provide, extended comment blocks (which can include markdown) are used [example]. The idea is to keep the documentation as close as possible to the implementation. It's much easier to forget to update a corresponding code example when changing an API if that example is kept in a far-off directory or even in a separate repository.
Finally, all of the above is automated by Netlify, so that each push to a specific branch triggers the docgen scripts, runs the results through Hugo and then publishes the docs to vendure.io!
Code Generation
Another way we leverage the type systems and transformation capabilities of TypeScript and GraphQL is by auto-generating code. Specifically, the GraphQL schema is used to generate TypeScript types which are then used to ensure that our server and client code is always in agreement with the data given and received by the GraphQL API. We use graphql-code-generator for this.
With this workflow, renaming a property in the API will raise build-time compiler errors in the client app code. This can be thought of as "end-to-end type safety".
Code Organization: Monorepo
The Vendure project consists of a server, a client, a number of server-side plugins and some common shared code. All of this code lives in a single git repository, known as a "monorepo". This makes a lot of sense for Vendure because the parts are tightly coupled in the sense that a change to a core API or a shared function will often necessitate an update to the dependencies of the client or one or more plugins. Additionally, each part (core, client, plugins, common) are published as separate packages on npm, all versioned in unison.
To ease the burden of keeping all of this in sync, we use Lerna. Lerna deals with keeping versions of the monorepo packages in sync and publishing a coherent set of packages to npm.
Even with the help of Lerna, coordinating the correct release of multiple packages can be very challenging. For this reason we make heavy use of Verdaccio, a npm-compatible package registry you can run locally. Some very tricky releases have seen over 10 not-quite-right publishes to Verdaccio before everything was just right, at which point we could confidently publish to npm.
Continuous Integration
We recently switched over to the recently-released GitHub Actions for running some automated testing and other workflows on each push. As well as the usual unit and end-to-end tests, we also test that Vendure can be correctly installed and run.
To do this, we again make use of Verdaccio and Lerna: in the CI container we install and run an instance of Verdaccio. Then the monorepo packages are built and published with Lerna to that local Verdaccio instance. Finally, we install and run Vendure to check that it all works. You can see the workflow configuration here.
Ad-hoc Tools
Finally, there are those custom tools written to handle some issue peculiar to the project. For instance, I ran into the problem where my IDE would sometimes auto-import a symbol from the wrong directory (getting confused by the monorepo setup). I didn't notice those three bad characters amongst the tens of imports at the top of the file. Everything worked locally but once published to npm, the release was broken.
Rather than continuing to rely on my own imperfect observation skills, I wrote a tiny script which checked for the bad import pattern, and if found the publish fails.
A point that is worth making here: don't be afraid to write your own tools. Sure, there are already open-source tools out there to solve most problems, but remember that each new dependency has both a cost and a relatively higher level of abstraction. Sometimes it is simply more efficient and maintainable to write a tool that is laser-focused on solving your issue and your issue alone. It's also a lot of fun!
Round up
The point of all this is to let the computer do what computers do well - repetitive, well-defined, exacting tasks - so that we have more time and attention to devote to those parts best suited to humans - planning, creating, problem solving.
This is by no means a complete or prescriptive account of The Right Way to manage your project. Vendure started out simple and manual; tools were gradually added as the need arose. In general YAGNI is a sound guide.
For convenience, here's a list of all the tools and services mentioned in the article. I would like to express my gratitude to the maintainers and contributors of all of these wonderful projects:
Linting & Formatting
Commit Messages & Changelogs
Documentation
Code Generation
Code Organization
Continuous Integration